



eBPF Documentation
eBPF es una tecnología revolucionaria con origen en el kernel de Linux que puede ejecutar programas en espacio aislado en un contexto privilegiado, como el kernel del sistema operativo. Se utiliza para ampliar de forma segura y eficiente las capacidades del kernel sin necesidad de cambiar el código fuente del kernel ni cargar módulos del kernel.
Históricamente, el sistema operativo siempre ha sido un lugar ideal para implementar funciones de observabilidad, seguridad y redes debido a la capacidad privilegiada del kernel para supervisar y controlar todo el sistema. Al mismo tiempo, es difícil evolucionar el kernel de un sistema operativo debido a su papel central y sus altos requisitos de estabilidad y seguridad. Por lo tanto, la tasa de innovación a nivel del sistema operativo ha sido tradicionalmente menor en comparación con la funcionalidad implementada fuera del sistema operativo.
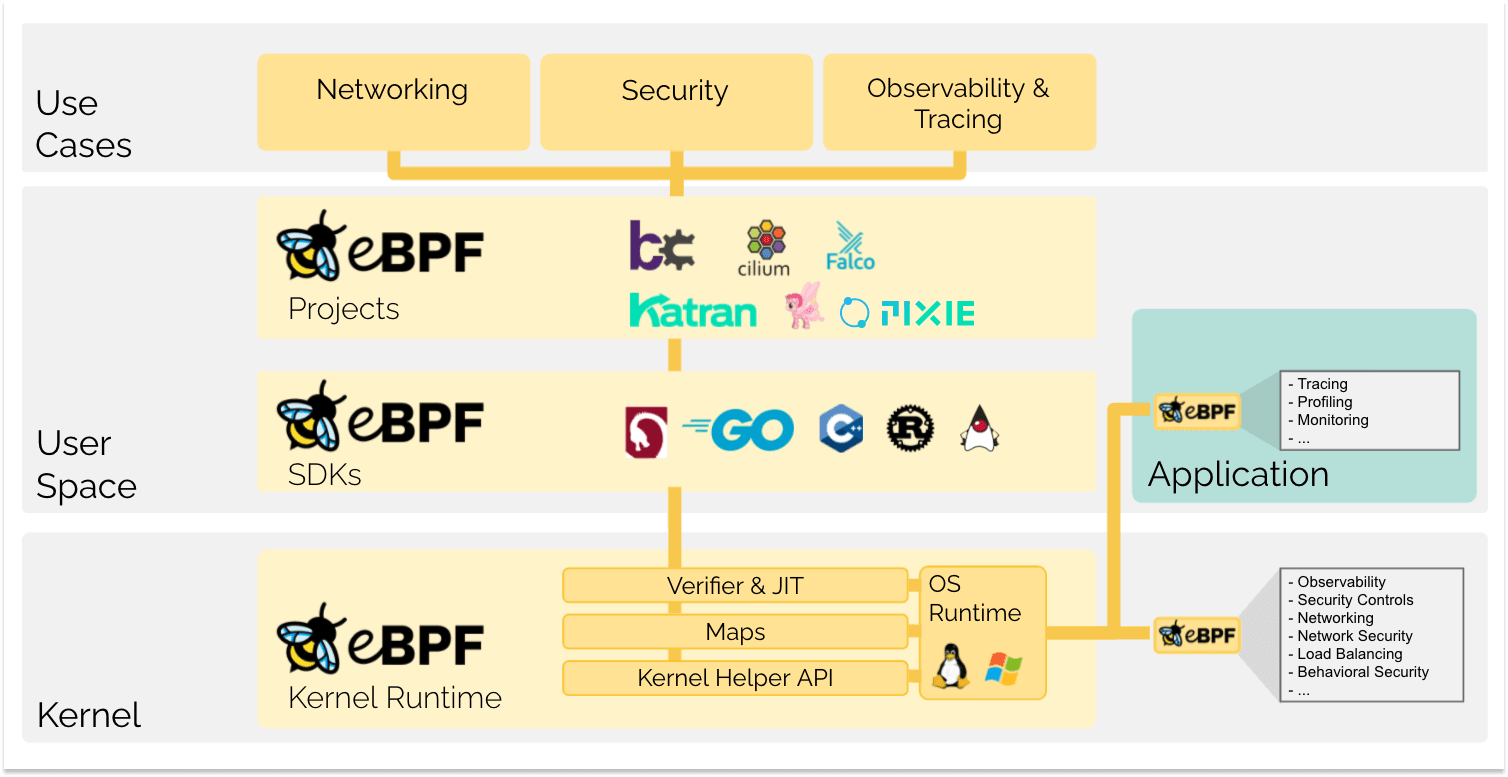
eBPF cambia esta fórmula fundamentalmente. Al permitir ejecutar programas en espacio aislado dentro del sistema operativo, los desarrolladores de aplicaciones pueden ejecutar programas eBPF para agregar capacidades adicionales al sistema operativo en tiempo de ejecución. Luego, el sistema operativo garantiza la seguridad y la eficiencia de ejecución como si estuviera compilado de forma nativa con la ayuda de un compilador Just-In-Time (JIT) y un motor de verificación. Esto ha dado lugar a una ola de proyectos basados en eBPF que cubren una amplia gama de casos de uso, incluidas las funciones de redes, observabilidad y seguridad de próxima generación.
Hoy en día, eBPF se utiliza ampliamente para impulsar una amplia variedad de casos de uso: proporcionar redes de alto rendimiento y balanceo de carga en centros de datos modernos y entornos nativos de la nube, extrayendo datos detallados de observabilidad de seguridad con baja sobrecarga, ayudando a los desarrolladores de aplicaciones a rastrear aplicaciones, proporcionando información para la resolución de problemas de rendimiento, aplicación preventiva de seguridad en tiempo de ejecución de contenedores y aplicaciones, y mucho más. Las posibilidades son infinitas y la innovación que eBPF está desbloqueando apenas ha comenzado.
eBPF.io es una plataforma destinada a que cualquier persona pueda aprender y colaborar en el proyecto eBPF. Se trata de una comunidad abierta en la que todos son bienvenidos a participar y compartir. Ya sea que estés buscando una introducción inicial a eBPF, necesites encontrar más material de lectura o estés interesado en dar tus primeros pasos como colaborador en los proyectos principales, eBPF.io te proporcionará la orientación y los recursos necesarios en tu camino.
Inicialmente, BPF representaba Berkeley Packet Filter, pero en la actualidad, con la versión de eBPF (extended BPF) que va mucho más allá de la simple filtración de paquetes, el acrónimo BPF ha perdido su significado original. eBPF ahora se considera como un término independiente que no se abrevia en particular. En el código fuente de Linux, aún se utiliza el término BPF, y en herramientas y documentación, los términos BPF y eBPF suelen usarse de manera intercambiable. Para distinguirlo del eBPF actual, a veces se hace referencia al BPF original como cBPF (BPF clásico).
La abeja es el logotipo oficial de eBPF y fue creada originalmente por Vadim Shchekoldin. En la primer Conferencia de eBPF, donde se realizó una votación y se le puso el nombre de eBee. (Para obtener detalles sobre los usos aceptables del logotipo, consulta las Guías de Marca de la Linux Foundation).
Los siguientes capítulos son una introducción rápida a eBPF. Si desea obtener más información sobre eBPF, consulte la Guía de referencia de eBPF y XDP. Si usted es un desarrollador que busca crear un programa eBPF o está interesado en aprovechar una solución que utiliza eBPF, es útil comprender la arquitectura y los conceptos básicos.
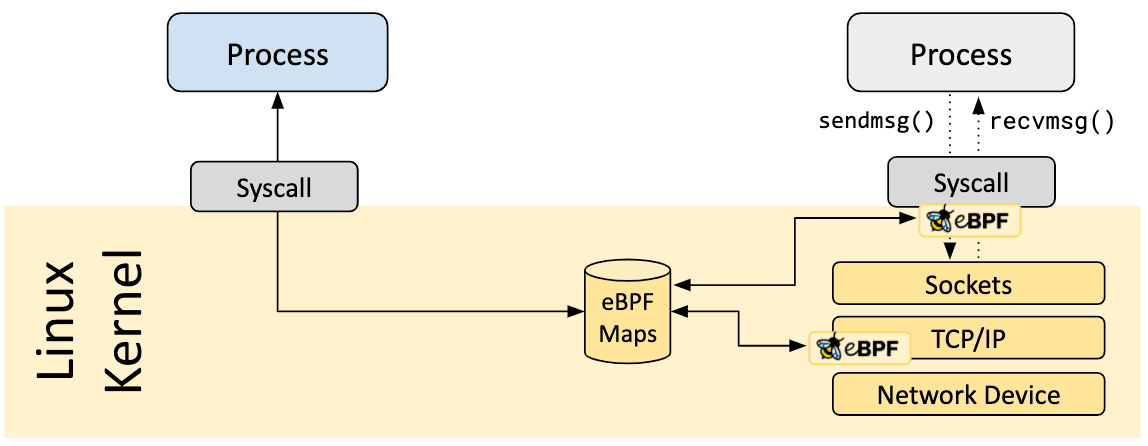
Los programas eBPF están controlados por eventos y se ejecutan cuando el kernel o una aplicación pasa por un determinado punto de enlace. Los hooks predefinidos incluyen llamadas al sistema, entrada/salida de funciones, puntos de seguimiento del kernel, eventos de red y muchos otros.

Si no existe un hook predefinido para una necesidad particular, es posible crear un rastro del kernel (kprobe) o un rastro del usuario (uprobe) para adjuntar programas eBPF casi en cualquier lugar del kernel o de las aplicaciones de usuario.
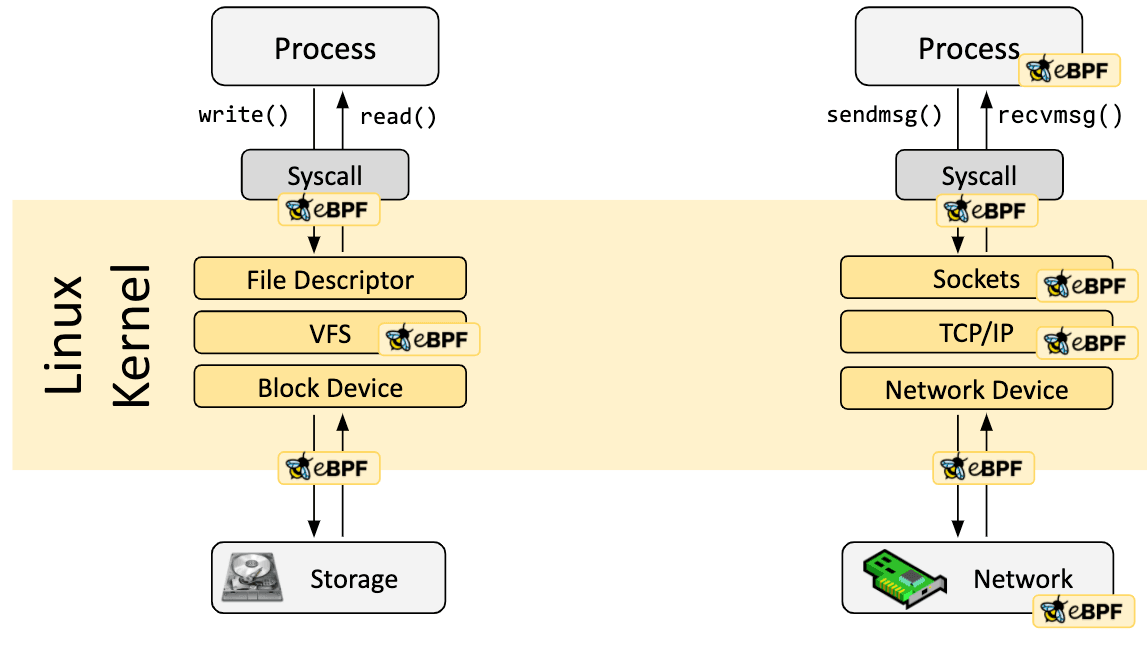
En muchos escenarios, eBPF no se usa directamente sino indirectamente a través de proyectos como Cilium, bcc o bpftrace, que proporcionan una abstracción mejor de eBPF y no requieren escribir programas directamente, sino que ofrecen la capacidad de especificar definiciones basadas en intenciones que son luego implementados con eBPF.

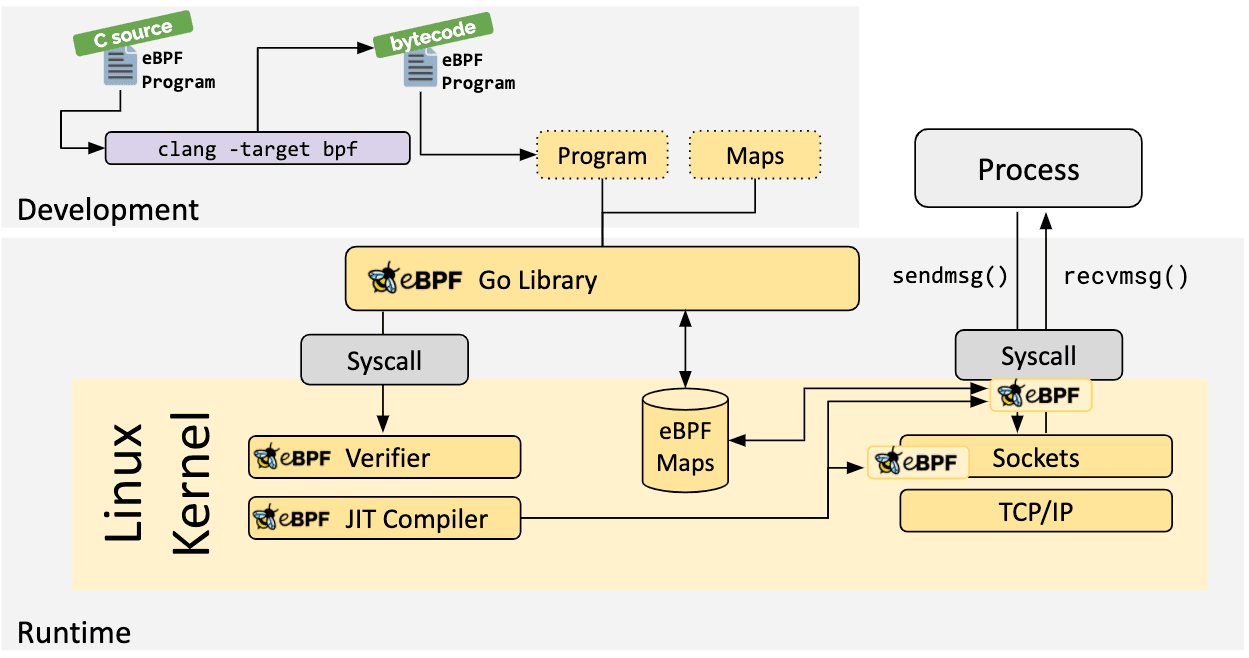
Si no existe una abstracción de nivel superior, los programas deben escribirse directamente. El kernel de Linux espera que los programas eBPF se carguen en forma de código de bytes. Si bien, por supuesto, es posible escribir código de bytes directamente, la práctica de desarrollo más común es aprovechar un conjunto de compiladores como LLVM para compilar código pseudo-C en código de bytes eBPF.
When the desired hook has been identified, the eBPF program can be loaded into the Linux kernel using the bpf system call. This is typically done using one of the available eBPF libraries. The next section provides an introduction into the available development toolchains.Una vez que se haya identificado el hookdeseado, el programa eBPF se puede cargar en el núcleo de Linux utilizando la llamada al sistema "bpf". Normalmente, esto se hace utilizando en una de las bibliotecas eBPF disponibles. En la siguiente sección proporcionamos una introducción a las herramientas de desarrollo disponibles.
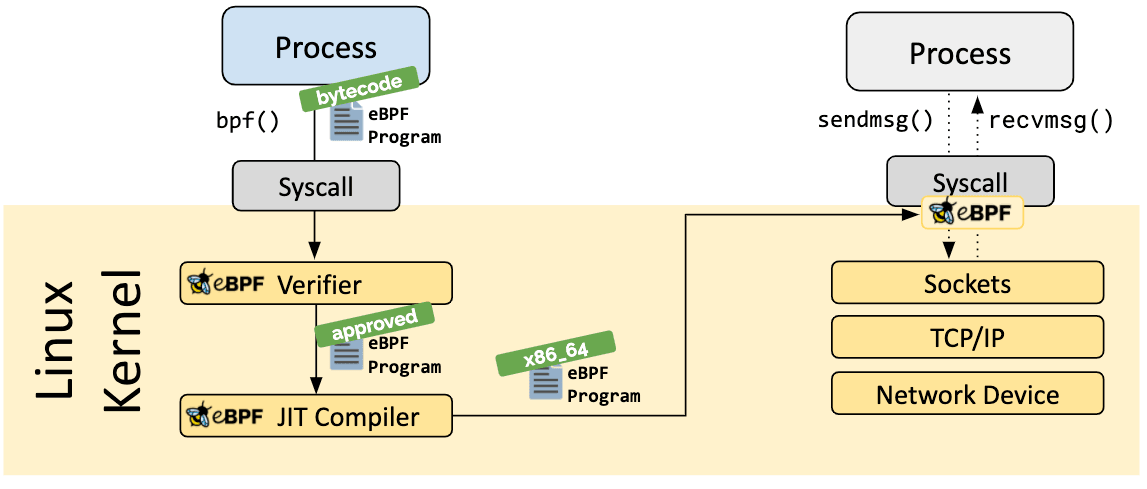
A medida que el programa se carga en el kernel de Linux, pasa por dos etapas antes de ser adjuntado al código solicitado:
El paso de verificación garantiza que el programa eBPF sea seguro de ejecutar. Valida que el programa cumpla con varias condiciones, por ejemplo:
- El proceso de carga del programa eBPF tiene las capacidades requeridas (privilegios). A menos que esté eBPF sin privilegios, solo los procesos privilegiados pueden cargar programas eBPF.
- El programa no falla ni daña el sistema.
- El programa siempre se ejecuta hasta su finalización (es decir, el programa no permanece en un bucle para siempre, retrasando el procesamiento posterior).
La etapa de compilación Just-in-Time (JIT) traduce el código de bytes genérico del programa al conjunto de instrucciones de la máquina para optimizar la velocidad de ejecución del programa. Esto hace que los programas eBPF se ejecuten tan eficientemente como el código del kernel compilado de forma nativa o como el código cargado como un módulo del kernel.
Un aspecto vital de los programas eBPF es la capacidad de compartir información recopilada y almacenar el estado. Para ello, los programas eBPF pueden aprovechar el concepto de mapas eBPF para almacenar y recuperar datos en un amplio conjunto de estructuras de datos. Se puede acceder a los mapas eBPF desde programas eBPF, así como desde aplicaciones en el espacio del usuario (user space) a través de una llamada al sistema (system call).
La siguiente es una lista incompleta de los tipos de mapas admitidos para comprender la diversidad de las estructuras de datos. Para varios tipos de mapas, está disponible una variación compartida y por CPU.
- Tablas hash, matrices
- LRU (menos utilizado recientemente)
- Búfer de anillo
- Seguimiento de pila
- LPM (coincidencia de prefijo más largo)
- ...
Los programas eBPF no pueden llamar a funciones arbitrarias del kernel. Permitir esto vincularía los programas eBPF a versiones particulares del kernel y complicaría la compatibilidad de los programas. En cambio, los programas eBPF pueden realizar llamadas a funciones auxiliares, una API estable y conocida que ofrece el kernel.

El conjunto de llamadas de ayuda disponibles está en constante evolución. Ejemplos de llamadas de ayuda disponibles:
- Generar números aleatorios
- Obtener fecha y hora actuales
- Acceso al mapa eBPF
- Obtener contexto de proceso/cgroup
- Manipular paquetes de red y lógica de reenvío
Los programas eBPF se pueden componer con el concepto de cola y llamadas a funciones. Las llamadas a funciones permiten definir y llamar funciones dentro de un programa eBPF. Las llamadas de cola pueden llamar y ejecutar otro programa eBPF y reemplazar el contexto de ejecución, de manera similar a cómo opera la llamada al sistema execve() para procesos regulares.
Un gran poder también debe conllevar una gran responsabilidad.
eBPF es una tecnología increíblemente poderosa y ahora se ejecuta en el corazón de muchos componentes críticos de la infraestructura de software. Durante el desarrollo de eBPF, la seguridad de eBPF fue el aspecto más crucial cuando se consideró la inclusión de eBPF en el kernel de Linux. La seguridad de eBPF se garantiza a través de varias capas:
Privilegios requeridos
A menos que esté habilitado eBPF sin privilegios, todos los procesos que pretendan cargar programas eBPF en el kernel de Linux deben ejecutarse en modo privilegiado (root) o requerir la capacidad CAP_BPF. Esto significa que los programas que no son de confianza no pueden cargar programas eBPF.
Si se habilita eBPF sin privilegios, los procesos sin privilegios pueden cargar ciertos programas eBPF sujetos a un conjunto de funcionalidades reducido y con acceso limitado al kernel.
Verificador
Si a un proceso se le permite cargar un programa eBPF, todos los programas aún pasan por el verificador eBPF. El verificador eBPF garantiza la seguridad del programa en sí. Esto significa, por ejemplo, es posible:
- Los programas se validan para garantizar que siempre se ejecuten hasta su finalización, p. Es posible que un programa eBPF nunca se bloquee o permanezca en un bucle para siempre. Los programas eBPF pueden contener los llamados bucles acotados, pero el programa sólo se acepta si el verificador puede garantizar que el bucle contiene una condición de salida que se garantiza que se cumplirá.
- Los programas no pueden utilizar variables no inicializadas ni acceder a la memoria fuera de los límites.
- Los programas deben ajustarse a los requisitos de tamaño del sistema. No es posible cargar programas eBPF arbitrariamente grandes.
- El programa debe tener una complejidad finita. El verificador evaluará todas las rutas de ejecución posibles y debe ser capaz de completar el análisis dentro de los límites del límite superior de complejidad configurado.
El verificador pretende ser una herramienta de seguridad que comprueba que los programas sean seguros de ejecutar. No es una herramienta de seguridad que inspecciona lo que están haciendo los programas.
Endurecimiento
Una vez completada con éxito la verificación, el programa eBPF se ejecuta a través de un proceso de endurecimiento según si el programa se carga desde un proceso privilegiado o no privilegiado. Este paso incluye:
- Protección de ejecución de programas: la memoria del kernel que contiene un programa eBPF está protegida y es de solo lectura. Si por alguna razón, ya sea un error del kernel o una manipulación maliciosa, se intenta modificar el programa eBPF, el kernel fallará en lugar de permitirle continuar ejecutando el programa dañado/manipulado.
- Mitigación contra Spectre: según se especula, las CPU pueden predecir erróneamente las ramas y dejar efectos secundarios observables que podrían extraerse a través de un canal lateral. Para nombrar algunos ejemplos: los programas eBPF enmascaran el acceso a la memoria para redirigir el acceso bajo instrucciones transitorias a áreas controladas, el verificador también sigue rutas de programa accesibles solo bajo ejecución especulativa y el compilador JIT emite Retpolines en caso de que las llamadas finales no se puedan convertir en llamadas directas. .
- Cegamiento constante: todas las constantes del código están cegadas para evitar ataques de pulverización JIT. Esto evita que los atacantes inyecten código ejecutable como constantes que, en presencia de otro error del kernel, podrían permitir a un atacante saltar a la sección de memoria del programa eBPF para ejecutar el código.
Contexto de tiempo de ejecución abstraído
Los programas eBPF no pueden acceder directamente a la memoria del kernel arbitraria. El acceso a datos y estructuras de datos que se encuentran fuera del contexto del programa debe realizarse a través de los asistentes de eBPF. Esto garantiza un acceso constante a los datos y hace que dicho acceso esté sujeto a los privilegios del programa eBPF, ejemplo: un programa eBPF en ejecución puede modificar los datos de ciertas estructuras de datos si se puede garantizar que la modificación sea segura. Un programa eBPF no puede modificar aleatoriamente las estructuras de datos en el kernel.
Comencemos con una analogía. ¿Recuerdas GeoCities? Hace 20 años, las páginas web solían estar escritas casi exclusivamente en lenguaje de marcado estático (HTML). Una página web era básicamente un documento con una aplicación (navegador) capaz de mostrarlo. Si observamos las páginas web hoy en día, se han convertido en aplicaciones completas y la tecnología basada en la web ha reemplazado a la gran mayoría de las aplicaciones escritas en lenguajes que requieren compilación. ¿Qué habilitó esta evolución?
La respuesta corta es la capacidad de programación con la introducción de JavaScript. Desencadenó una revolución masiva que resultó en que los navegadores se convirtieran en sistemas operativos casi independientes.
¿Por qué ocurrió esta evolución? Los programadores ya no estaban tan limitados por los usuarios que ejecutaban versiones específicas de navegadores. En lugar de convencer a los organismos de que se necesitaba una nueva etiqueta HTML, la disponibilidad de los bloques necesarios para la construcción, desacopló el ritmo de innovación del navegador subyacente en comparación con la aplicación que se ejecutaba sobre él. Por supuesto, esta explicación es un poco simplificada, ya que HTML evolucionó con el tiempo y contribuyó al éxito, pero la evolución de HTML por sí sola no habría sido suficiente.
Antes de tomar este ejemplo y aplicarlo a eBPF, echemos un vistazo a un par de aspectos clave que fueron vitales en la introducción de JavaScript:
- Seguridad: El código no confiable se ejecuta en el navegador del usuario. Esto se resolvió mediante la creación de un entorno seguro para los programas JavaScript y abstrayendo el acceso a los datos del navegador.
- Entrega Continua: La evolución de la lógica del programa debe ser posible sin necesidad de enviar constantemente nuevas versiones del navegador. Esto se logró proporcionando los componentes de bajo nivel adecuados para construir lógica arbitraria.
- Rendimiento: La capacidad de programación debe ofrecerse con un sobrecosto mínimo. Esto se resolvió con la introducción de un compilador Just-in-Time (JIT). Para todos los casos mencionados anteriormente, se pueden encontrar contrapartes exactas en eBPF por la misma razón.
Ahora volvamos a eBPF. Para comprender el impacto de la capacidad de programación de eBPF en el kernel de Linux, es útil tener una comprensión de alto nivel de la arquitectura del kernel de Linux y cómo interactúa con las aplicaciones y el hardware.
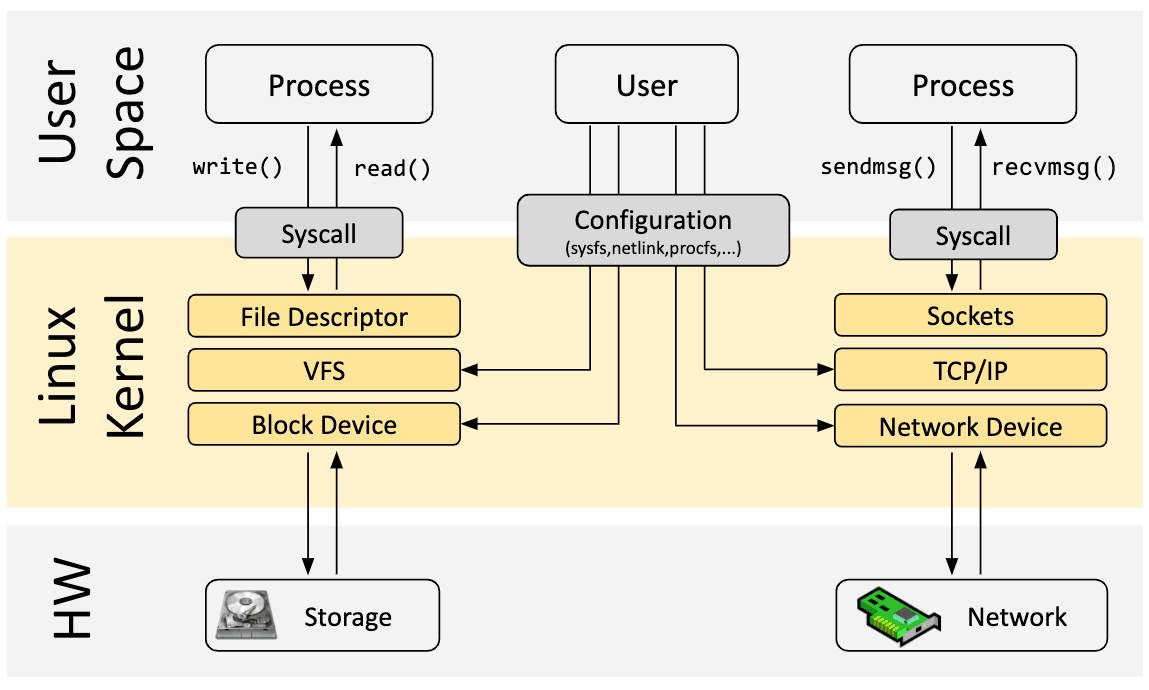
El propósito principal del kernel de Linux es abstraer el hardware físico o virtual y proporcionar una API consistente (llamadas al sistema) que permita que las aplicaciones se ejecuten y compartan los recursos. Para lograr esto, se mantienen una amplia variedad de subsistemas y capas para distribuir estas responsabilidades. Cada subsistema generalmente permite cierto nivel de configuración para adaptarse a las diferentes necesidades de los usuarios. Si un comportamiento deseado no se puede configurar, se requerirá un cambio en el kernel, lo que históricamente dejaba dos opciones:
Soporte al Código fuente
- Cambiar el código fuente del kernel y convencer a la comunidad del kernel de Linux de que el cambio es necesario.
- Esperar varios años para que la nueva versión del kernel se convierta en un estándar.
Módulo del Kernel
- Escribir un módulo del kernel.
- Actualizarlo regularmente, ya que cada lanzamiento del kernel puede romperlo.
- Correr el riesgo de corromper tu kernel de Linux debido a la falta de límites de seguridad.
Con eBPF, está disponible una nueva opción que permite reprogramar el comportamiento del kernel de Linux sin necesidad de realizar cambios en el código fuente del kernel o cargar un módulo del kernel. En muchos aspectos, esto es muy similar a cómo JavaScript y otros lenguajes de scripting desbloquearon la evolución de sistemas que se habían vuelto difíciles o costosos de cambiar.
Existen varias herramientas de desarrollo que ayudan en el desarrollo y gestión de programas eBPF. Todas ellas abordan diferentes necesidades de los usuarios:
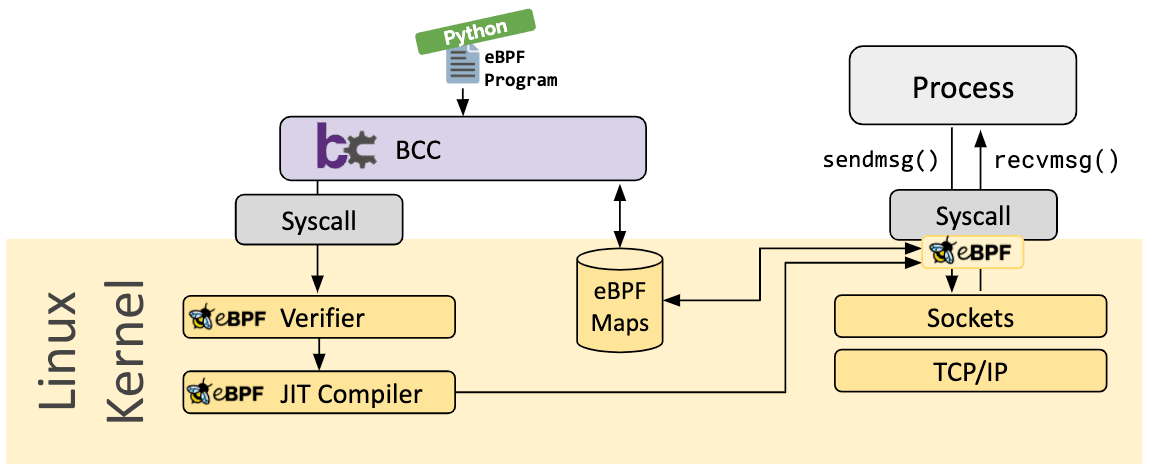
bcc
BCC es un framework que permite a los usuarios escribir programas python con programas eBPF incrustados en su interior. El framework está dirigido a los casos de uso que implican la generación de perfiles/rastreo de aplicaciones y sistemas en los que se utiliza un programa eBPF para recopilar estadísticas o generar eventos intuitivos y un homólogo en el espacio de usuario recopila los datos y los muestra en un formato legible para el ser humano. La ejecución del programa python generará el bytecode eBPF y lo cargará en el kernel.
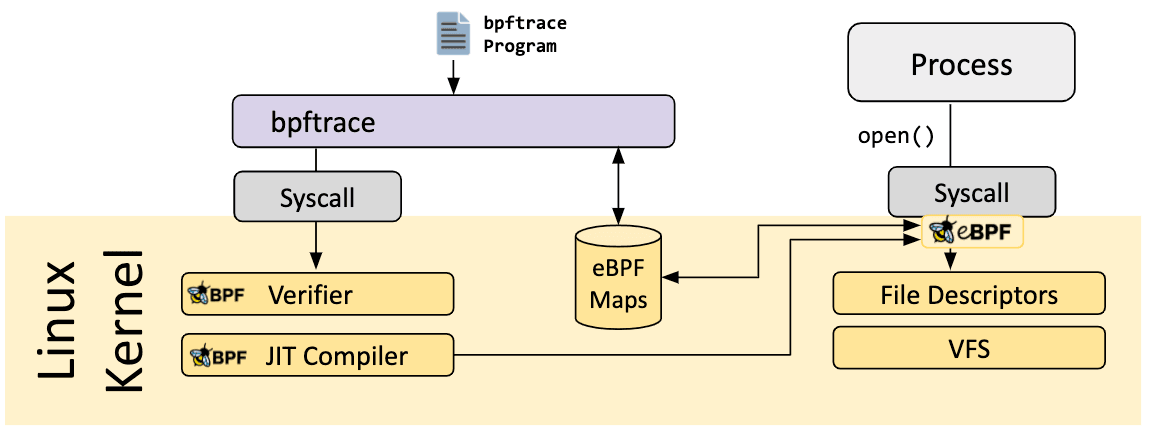
bpftrace
bpftrace es un lenguaje de rastreo de alto nivel para Linux eBPF y está disponible en kernels de Linux semi-recientes (Version 4.x). bpftrace utiliza LLVM como backend para compilar scripts a bytecode eBPF y hace uso de BCC para interactuar con el subsistema Linux eBPF así como con las capacidades de rastreo existentes en Linux: rastreo dinámico del kernel (kprobes), rastreo dinámico a nivel del usuario (uprobes) y tracepoints. El lenguaje bpftrace está inspirado en awk, C+ y trazadores predecesores como DTrace y SystemTap.
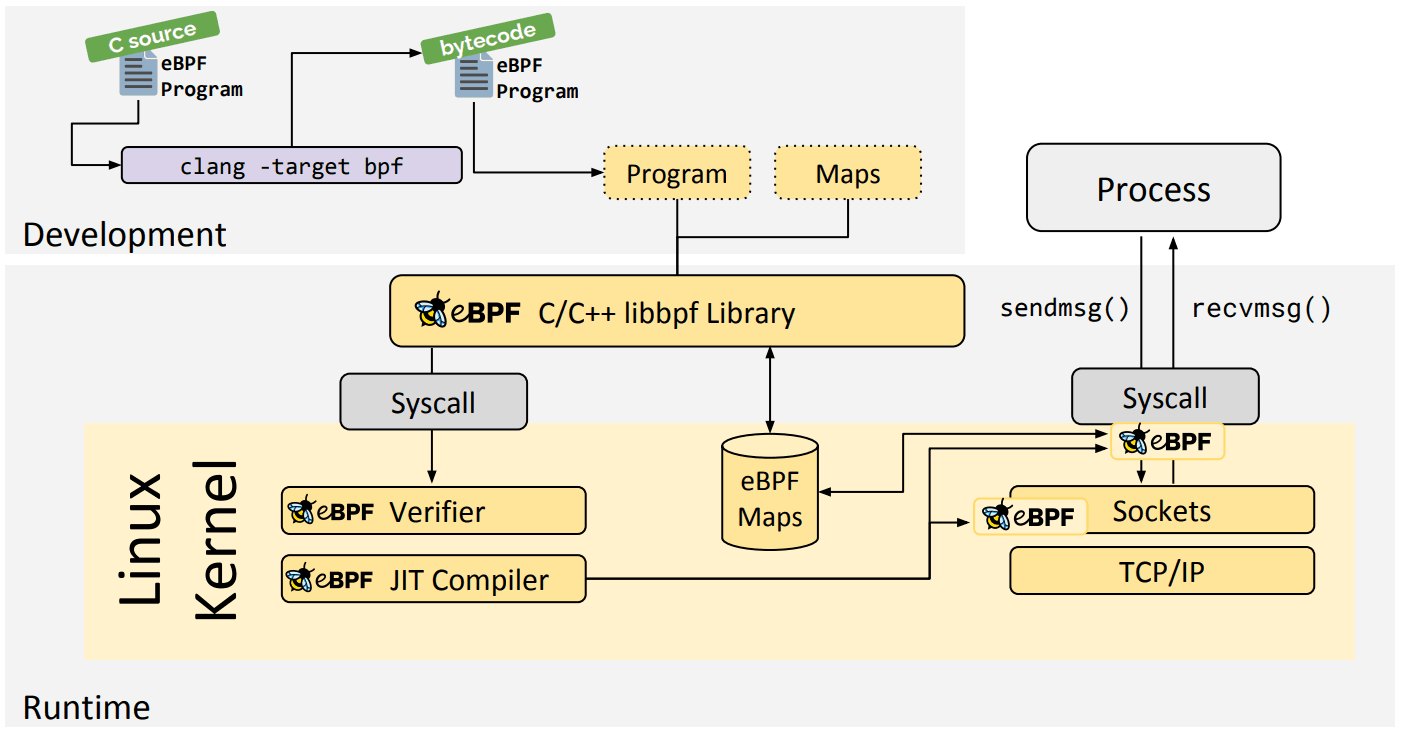
Biblioteca Go de eBPF
La biblioteca Go de eBPF proporciona una biblioteca genérica de eBPF en que puedes ver todo el proceso de llegar al bytecode de eBPF y la carga y gestión de programas eBPF. Los programas eBPF se crean normalmente escribiendo un lenguaje de alto nivel y luego utilizan el compilador clang/LLVM para compilar al bytecode de eBPF.
Biblioteca libbpf C/C++
La biblioteca libbpf es una biblioteca eBPF genérica basada en C/C++ que ayuda a entender y desacoplar la carga de archivos objeto eBPF generados desde el compilador clang/LLVM en el núcleo y, en general, abstrae la interacción con la llamada al sistema BPF proporcionando API de biblioteca fáciles de usar para las aplicaciones.
Si deseas saber más sobre eBPF, continúa leyendo los siguientes materiales adicionales:
- eBPF Docs, Technical documentation for eBPF
- BPF & XDP Reference Guide, Cilium Documentation, Aug 2020
- BPF Documentation, BPF Documentation in the Linux Kernel
- BPF Design Q&A, FAQ for kernel-related eBPF questions
- Learn eBPF Tracing: Tutorial and Examples, Brendan Gregg's Blog, Jan 2019
- XDP Hands-On Tutorials, Various authors, 2019
- BCC, libbpf and BPF CO-RE Tutorials, Facebook's BPF Blog, 2020
- eBPF Tutorial: Learning eBPF Step by Step with Examples, Various authors, 2024
Generic
- eBPF and Kubernetes: Little Helper Minions for Scaling Microservices (Slides), Daniel Borkmann, KubeCon EU, Aug 2020
- eBPF - Rethinking the Linux Kernel (Slides), Thomas Graf, QCon London, April 2020
- BPF as a revolutionary technology for the container landscape (Slides), Daniel Borkmann, FOSDEM, Feb 2020
- BPF at Facebook, Alexei Starovoitov, Performance Summit, Dec 2019
- BPF: A New Type of Software (Slides), Brendan Gregg, Ubuntu Masters, Oct 2019
- The ubiquity but also the necessity of eBPF as a technology, David S. Miller, Kernel Recipes, Oct 2019
Deep Dives
- BPF and Spectre: Mitigating transient execution attacks (Slides) , Daniel Borkmann, eBPF Summit, Aug 2021
- BPF Internals (Slides), Brendan Gregg, USENIX LISA, Jun 2021
Cilium
- Advanced BPF Kernel Features for the Container Age (Slides), Daniel Borkmann, FOSDEM, Feb 2021
- Kubernetes Service Load-Balancing at Scale with BPF & XDP (Slides), Daniel Borkmann & Martynas Pumputis, Linux Plumbers, Aug 2020
- Liberating Kubernetes from kube-proxy and iptables (Slides), Martynas Pumputis, KubeCon US 2019
- Understanding and Troubleshooting the eBPF Datapath in Cilium (Slides), Nathan Sweet, KubeCon US 2019
- Transparent Chaos Testing with Envoy, Cilium and BPF (Slides), Thomas Graf, KubeCon EU 2019
- Cilium - Bringing the BPF Revolution to Kubernetes Networking and Security (Slides), Thomas Graf, All Systems Go!, Berlin, Sep 2018
- How to Make Linux Microservice-Aware with eBPF (Slides), Thomas Graf, QCon San Francisco, 2018
- Accelerating Envoy with the Linux Kernel, Thomas Graf, KubeCon EU 2018
- Cilium - Network and Application Security with BPF and XDP (Slides), Thomas Graf, DockerCon Austin, Apr 2017
Hubble
- Hubble - eBPF Based Observability for Kubernetes, Sebastian Wicki, KubeCon EU, Aug 2020
- Learning eBPF, Liz Rice, O'Reilly, 2023
- Security Observability with eBPF, Natália Réka Ivánkó and Jed Salazar, O'Reilly, 2022
- What is eBPF?, Liz Rice, O'Reilly, 2022
- Systems Performance: Enterprise and the Cloud, 2nd Edition, Brendan Gregg, Addison-Wesley Professional Computing Series, 2020
- BPF Performance Tools, Brendan Gregg, Addison-Wesley Professional Computing Series, Dec 2019
- Linux Observability with BPF, David Calavera, Lorenzo Fontana, O'Reilly, Nov 2019
- BPF for security - and chaos - in Kubernetes, Sean Kerner, LWN, Jun 2019
- Linux Technology for the New Year: eBPF, Joab Jackson, Dec 2018
- A thorough introduction to eBPF, Matt Fleming, LWN, Dec 2017
- Cilium, BPF and XDP, Google Open Source Blog, Nov 2016
- Archive of various articles on BPF, LWN, since Apr 2011
- Various articles on BPF by Cloudflare, Cloudflare, since March 2018
- Various articles on BPF by Facebook, Facebook, since August 2018